Bots & Analytics, II: From Filtering out Bots to Filtering in Humans
“Hard” & “Soft” Bots, Human Signals — and Vacation in Cleveland
Recap: Why common Bot combat methods aren’t good enough for Analytics
In part I, we looked at common Bot Detection / Filtering methods. We concluded they are not what we really need for common Web Analytics solutions like Google Analytics or Adobe Analytics, but also for UX tools (e.g. Hotjar), trackers from ad networks (Google Ads/Facebook/etc.), pricing or AB testing tools — in short, basically anything that runs off of Tag Management Systems. The most important reasons why even expensive 3rd-party Bot Detection solutions fail were:
- Their detection comes too late => At the moment when they know it is a Bot, the data is already in your Analytics/Google Ads/Facebook Pixel/Floodlight/Hotjar/Adobe Target/Server-Side Tag Management System. That costs you double: you usually pay these tools per Server Call (= for each Hit of data you send to them), and filtering that data out after-the-fact is ginormously tedious to impossible.
- They still have too many false positives/negatives, i.e. they miss out on too many Bots or identify humans as Bots too often => Relying on their judgment would lose you too much human traffic and you’d still have too much Bot traffic in your data
The Bot Rush and the Desperation
So when when this client’s Bot traffic increased from 10% to 40–50% of all Visits, I was more and more desperate. So far, the Bot Filtering in Adobe Analytics was mainly done by using Virtual Report Suites (VRS) with a complex filter on top for Bot/Erroneous Traffic (e.g. fraudulent Transactions or data caused by tracking errors). The filter (technically a “segment”) is part domain/browser/geo criteria, part behaviour (e.g. Visits with >n Pageviews, but no Cart Additions or Logins/Orders) and applies retroactively, unlike Google Analytics View Filters (see more in part I, “C: Apply and Maintain Custom Filters / VRS Segments”). This allowed us to stay afloat by occasionally updating the Bot Filters, and we didn’t have to bother users with bs like “you need to put the Bot Filter Segment on top of every report first”.

But now, the Bot traffic increased so heavily and so quickly. That meant this approach was no longer enough:
- 40% Bots meant 40% more Server Calls => higher license fees for Adobe Analytics, Tealium Event Stream (Server-Side Tag Management), Hotjar, Optimizely, etc.
- New Bots (or say, new “disguises”) appeared every day. We would have had to update the VRS filters all the time (e.g. add 100 new ISP domains on Monday and another 100 on Tuesday etc…).
- Eventually, the segment behind the Bot Filters would become too complex, slowing down reporting or leading to the “segment too long” error
IT: “These Bots are not our focus”
I felt like Syisphus and did not sleep much. The IT Security team’s pricey “AI-driven” Bot Management system identified only a tiny fraction of these Bots, so having them simply block these Bots from accessing the site (my first idea) was not an option. Updating their solution’s algorithms with the insights from the Adobe data would cost money and take months.
Moreover, the Bots that hit the Analytics data were none of the IT team’s concern, as they did not put an excessive load on the servers, and they did not pose a security risk (e.g. they did not attempt fraud purchases). Most of these Bots simply crawled product detail and search results pages in a rather “human” way (e.g. with ever-changing IP addresses and cookies and with a rather normal Single-Page Visit Rate). So I gave up on IT help after some weeks.
But the goal was clear:
We had to prevent as many Bots as possible from getting tracked in the first place. This meant we had to find a way to identify most of the Bots client-side and prevent any tracking even before the first Pageview. The existing filtering logic in Analytics would then be relegated to a second layer.
What we eventually built looks like this (higher resolution image):

How did we get to this system and what does this all mean? Read on.
Layer 1: Soft Bots, Hard Bots, and Human Signals
The Consent Manager as an inadvertent Bot Prevention System
I was still desperate because I didn’t see a way to ever efficiently combat these Bots. Then, one of these random things happened. I did a completely unrelated analysis of the impact of an opt-in Consent Manager for another client. This Consent Manager required users to click “I accept cookies” in an overlay when visiting their site for the first time. No acceptance, no tracking.
I noticed that the share of human traffic increased massively to nearly 100%. since the Consent Manager had been introduced — Bots seemed incapable of clicking that “Accept” button. So the Consent Manager had an unexpected side effect: It solved their Bot traffic problem in Analytics.
What do Humans do that Bots don’t?
This made us rethink the approach to Bot filtering. Instead of filtering Bots out, how about filtering humans in? Clicking “Accept” seemed to be a clear human signal! So there must be others.
The idea was:
- Let’s find a clearly defined, large chunk of the traffic that is so contaminated by Bots (>95%) that we can risk declaring it as “botty by default” and not track it.
- If a visitor from that botty chunk however gives us a “human signal”, tracking would start.
This is the 1st Layer’s crucial “Soft Bot” logic in a nutshell (see diagram above). This logic handles over 90% of all the Bots.
Let’s analyze — First, get the “botty by default” candidate!
So we deep-dove into the Adobe Analytics data, analyzing the “Bottiness Rate” for a lot of interactions and characteristics to see which chunk of our traffic could be declared as “botty by default”. This metric is built on top of a slightly stripped version of the segment that we also use for the Virtual Report Suite filter (see above) to spare Analytics users from botty data. To not overvalue signals that are common for both humans and Bots, Counter Metrics played a big part:
Counter Metrics measure the frequency of clear human interactions. As an example, Bots almost never log in, and they also don’t buy, which is why “% Visits with Login” and the Conversion Rate (Orders / Visits) are good Counter Metrics. If we see a 97% Bottiness Rate for Direct traffic from Germany, but also a 0.51% Conversion Rate, the Bottiness Rate likely is misleading in this case, and Direct traffic from Germany should not be declared as “botty by default”.
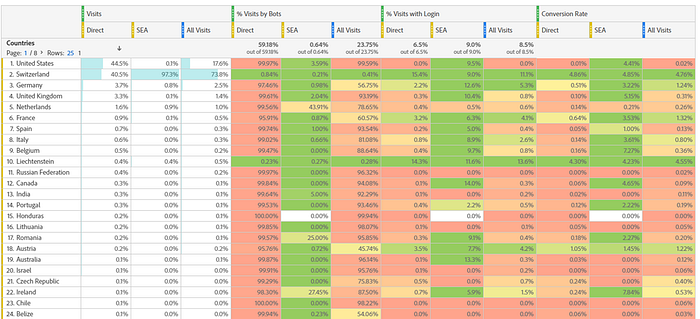
Americans are Bots — but what about Cleveland?
In the screenshot above, we clearly see that — in the case of this client (NOT generally, of course!) — “Direct” traffic from outside of Switzerland and Liechtenstein (especially USA) was already so voluminous (almost half the traffic) and so botty that it was a good segment to focus our efforts on for the first, client-side layer: If we could at least prevent our TMS from tracking those, we would already have 90% less spam in our data. Thus, the non-Swiss Direct traffic (very simplified here) became the “botty by default” traffic.
So >99% of U.S. Americans are spammy Bots — maybe that explains why so many voted for a spammer like Donald Trump. But still, a tiny fraction of those Americans are normal after all and still haven’t left the country! Some even buy things in that Swiss shop! Some might be Swiss citizens on vacation in Cleveland!
Secondly, find human signals
But how do we identify the humans among all those Bots from the USA (and the rest of the world)? Let’s focus on what the Bots among them do compared to what nearly only humans do and try to extract other human signals (apart from the already known obvious candidates “login” and “purchase”).
These human signals need to be identifiable client-side via the Tag Management System. This includes geolocation, because with Tealium’s built-in Consent Management logic, you can get the geolocation of a user into the Data Layer — even if you don’t use their Consent Manager (another unexpected side effect of Consent Management).
Signals can be certain interactions (e.g. Cart Addition) as well as characteristics (geolocation, URL parameters (e.g. “came via newsletter”), referrer, Data Layer variable X etc.). Luckily, this client has a rich Data Layer and tracks all kinds of user interactions. That paid off: We had many clear signals to compare.
See this example that looks at all non-Swiss Direct Traffic (our “botty by default” candidate):

The “Product Actions” in the table represent the different ways in which people can interact with products (view detail page, view a list of products, check the product specifications etc…). The Bottiness Rate of the non-Swiss “Direct” visitors is extremely high for “detail” and “list”. Taking the extremely low rates in the Counter Metrics (“% Logged-in Hits” and the “Participation Conversion Rate“) into account, we can safely assume that viewing a Product Detail Page or a Product List are not suitable as a “human signal”.
On the other hand, we see that e.g. the Bottiness Rate for “slider” (clicking image sliders on product detail pages) is only at 57.79%. 22% are logged in while clicking, and 12% end up ordering in the same Visit. That means clicking sliders is a pretty good sign for a human. Remember, our goal at this stage is not to find Bots, but to see which signals among the “botty by default” traffic are most likely humans (we don’t need a guarantee).
So we can use the “slider” Product Action and most of the other ones to give humans the benefit of the doubt: If we see that someone clicks a product image in a slider, our first layer of Bot Filtering will say “okay, you are likely a human, I will track you”. So Product Action “slider” becomes a “human whitelisting signal” in the “Soft Bot” logic of Layer 1.
How is this implemented in the TMS?
So in practice (in the TMS), each Data Layer Event from previously unknown Users that arrive via Direct Traffic from outside of Switzerland has to pass a check against many whitelisting criteria. If the Event’s payload does not fit a whitelisting criterion (e.g. if it is only a simple Product Detail View and the user is not logged in), tracking is prevented and the Visitor is declared a “Soft Bot”. “Soft” because there are many whitelisting criteria that can “turn a Bot into a human”, unlike the “Hard Bots” which have only very few whitelisting criteria. Hard Bots are identified by User Agents, URL Parameters etc. that are known to be 100% botty (e.g. Pingbots our IT uses for uptime checks or known Bots from brands that check certain product features).
So as soon as the American suspected (Soft) Bot does something human, e.g. logging in or clicking on the image slider, she gets “whitelisted”, and everything she does from now on is tracked. The “Hard” Bot however can click as many image sliders as he likes, we will only whitelist him if he effectively buys something or logs in (and we report this rare event via Adobe Analytics Alerts to check if the logic has a flaw).
Once whitelisted as a human, the info gets stored in the browser. Ensuing Data Layer Events are then not run against all these “human signal” checks anymore.
Don’t we lose real human traffic this way?
Yes, we do. But since it is only Direct Traffic and because we start tracking as soon as the user does something meaningful, e.g. put a product in the basket (=whitelisting criteria), the traffic we lose this way is meaningless. Especially with the masses of Bots we don’t track anymore, it is a tiny sacrifice. And even measured in total numbers, the lost traffic is minimal:

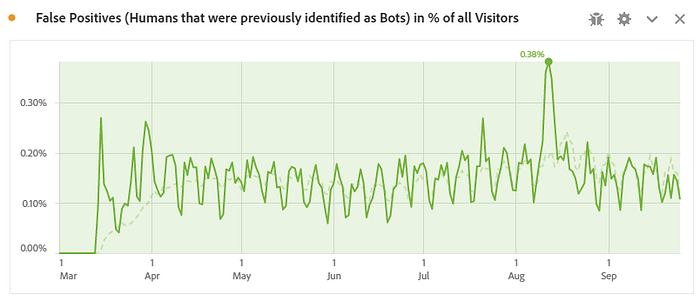
In other words, 0.5% of Bot Visits and Visitors and 2.9% of all Bot Hits were actually likely from humans after all. That was just 0.2%/0.1%/0.3% of all Visits, Visitors and Hits. The impact on the Conversion Rate of not having these Visits was an increase by 0.015 percentage points, so completely negligible as well.
Dry-running the system takes away the unknown unknowns
How do we know how many Bots we exclude with this system if we don’t track the Bots anymore? Because we built the system in a way that we can dry-run it at any time: When in “dry-run” mode, instead of actually preventing tracking, we can simply mark the traffic that we would have prevented from tracking. We did this extensively before going live, adjusting both the whitelisting and the geolocation criteria (for the “botty by default” traffic).
Furthermore, even when in “wet-run” mode, we track the fact that somebody is whitelisted after having previously been mistaken for a Bot. We also track the type of signal (e.g. “added product to cart”) that was responsible for whitelisting, so we see which signals may need to be tuned because they too often misidentify humans even though they are Bots. And if we find that a Swiss tourist colony has established itself in Cleveland and continues to visit our shop to order chocolate for their children at home, we can remove Cleveland from the “botty by default” logic.
And what about Bots from Switzerland?
I hear you yelling: “But aren’t those ‘Soft Bot’ criteria too soft and let a lot of actual Bots slip through? And what about Bots from Switzerland? Don’t they all fall through this first layer?” You are right. That’s why we still have the second layer:
Layer 2: Fall-Through Filtering in Analytics
The first layer’s goal was to not let in as much traffic as possible, traffic which can justifiably be regarded as “botty by default”. The reason for this goal, again, is to avoid botty data going into any system in the first place, because you pay per tracked Hit, because it is extremely tedious to impossible to get such data out again, because it slows down all queries, etc… In our case, this first layer covers over 95% of Bot traffic. Yes, we have a grateful case, being in Switzerland, and most Bots being evil foreigners (some parties would copy that statement). For other organizations, it should still be possible though to get a solid 80% of the Bot traffic caught by the first layer. An analysis of the data, as sketched above, will help you identify your “most botty chunk”.
Still, there are Bots that “fall through” because we don’t want to be overzealous with our client-side logic and exclude too many humans. For this, we still need the Virtual Report Suite logic with custom retroactive filters on top. These filters are based e.g. on network domain names typical for Swiss Bots or they look for “crawler-like behaviour” that can be assessed only after a Visit has completed (see part I, “C: Apply and Maintain Custom Filters / VRS Segments”).
Epilogue
Monitor your Engines
I sleep well again. No more constant segment updates in Analytics, no more reports that change if you look at them again tomorrow. But you need to monitor such a system rigorously and constantly. If Bots start behaving differently tomorrow, and if they do that in large swaths, you will need to adjust the logic. As mentioned, you need to monitor the rate of false positives, and you should do an occasional dry-run. You can also use those insufficient (for Analytics) 3rd-party Bot Detection systems as benchmarks (“Are we still better than system X? Does X find some clearly botty criteria that we miss?”). And if the 3rd-party system can feed signals back into the browser — can we use their “is human” verdict as an additional human whitelisting criteria in the first layer?
A little help from the vendors would be nice…
All in all, it would be great if the tool vendors did more about the Bot problems, as I sense that this is a grave and recurring topic almost everywhere. Why do we have to pay for Server Calls caused by Bots? Why are there no (or no easy) methods to e.g. delete data retroactively? Right now, Analytics admins are left stranded with a problem that can be huge, as the numbers in this article show. And it will get worse with the shift to more and more server-side tracking.
Share your approach!
For those who expected a silver bullet to “get rid of all Bots with 3 clicks”, you probably haven’t read this far anyway, but there is none. The way to reduce botty data to the point where it does not hurt anymore requires you to do your job as a Digital Analyst: Understand your data, and analyze it profoundly. But that’s fun! And if you have another solution, I am curious to learn from you in the comments!
